
Few people alive understand these systems better than Andrej Karpathy. He has trained neural networks for a living since before most of us could spell "transformer." So when he says this, the rest of us can exhale:
I have never felt more behind as a programmer.
If the expert at the front of the room feels behind, that feeling is not measuring your skill. It is measuring the volume in the room.
And the volume is deafening.
You are not behind. You are flooded. Those are different problems, and only one of them is yours to fix.
Here is a different way through it. Instead of one more sermon about AI, let me hand you the field manual: the things everyone repeats about AI coding, sorted into what is true, what is half-true, and what is simply being sold to you. One rule runs underneath all of them:
An LLM is a tool, not an oracle.
Let's take the claims one at a time.
Claim 1: "AI is intelligent."
It isn't. Not in the way the word implies.
The phrase "artificial intelligence" was a marketing decision from the start. John McCarthy coined it for a 1956 workshop, and writer Pablo Sanguinetti argues the term has misled us ever since, partly by describing a 1955 aspiration as if it were an accomplished fact.
So split the word in two and the fog clears…
Theoretical AI is the science-fiction mind. It wants things. It understands them. It does not exist, and it may never exist.
Practical AI is the thing on your screen: a statistical pattern machine that predicts plausible next tokens from a mountain of text and code. That is the entire trick.
Edsger Dijkstra called this decades ago:
The question of whether machines can think is about as relevant as the question of whether submarines can swim.
A submarine crosses oceans without swimming. A model writes code without understanding it.
Karpathy's image is even sharper.
LLMs are ghosts, not animals.
No drives, no body, no instinct, none of the biology that makes human reasoning cohere. Their intelligence is jagged. The same model that refactors a hundred-thousand-line codebase will then flunk a question a child could answer.
It is not thinking. It is pattern. Treat it that way, and it stops surprising you.
The model speaks fluent code. It does not know what your code is for.
Claim 2: "If you're not all-in, you're falling behind."
Half-true, and the dangerous half.
You cannot opt out. Your teammates use these tools. Your competitors use them. The pull requests landing in your repo were partly model-written whether anyone admits it or not.
But "you can't opt out" is not the same as "rush in and trust it."
The real choice was never whether AI enters your workflow. It is how. And the wrong how is not loud. It does not crash today. It quietly costs you later, in ways the rest of this post will make concrete.
Who profits if you believe it?
The doomer selling a newsletter and the founder selling a seat both need you scared or dazzled. Neither needs you clear-headed. When a claim about AI makes you feel panic or euphoria, follow the money before you follow the advice.
Claim 3: "It makes you faster."
Let's be honest.
It does make you faster. I am not going to pretend otherwise. Claude Code has become a real part of how I build Laravel apps and Statamic sites.
Where it genuinely shines for me:
Scaffolding the boring 80%. Models, migrations, form requests, resource controllers, and factories. The conventional Laravel plumbing, which it has seen ten thousand times, gets right on the first pass.
Tests I would have skipped under a tight deadline. It drafts Pest coverage, and I refine instead of starting from a blank file.
The first draft of a refactor. Point it at a fat controller and ask for a service class or an action.
Explaining unfamiliar code. Dropped into a legacy codebase, it reads faster than I do and tells me where to look.
So this is not a skeptic telling you the tools do nothing. Anyone saying that has not run them properly. Used well, inside a domain I know well, an agent saves me real hours every week.
So the interesting question is not whether it makes you faster. It is who, by how much, and at what cost over time.
And there, the actual numbers get slippery.
OpenAI's own report found enterprise users save roughly 40 to 60 minutes a day. Useful. Not a revolution. Then it gets stranger. A controlled study from METR watched experienced open-source developers work with and without AI tools in early 2025, and they took 19% longer with the tools while reporting that they felt faster the whole time.
Feel the gap in that sentence. They felt faster. They were slower.
Now here is the part that keeps me honest in the other direction. METR ran the experiment again in late 2025, and the newer data points the opposite way, suggesting a speedup of around 18% for returning developers and 4% for new ones. Sounds like the tools just got good, right?
Not so fast.
METR themselves call it an unreliable signal, and the reason matters.
To measure what AI does, you need developers willing to work both with it and without it. But the ones who benefit most now refuse to code without it, so they drop out of the no-AI group. The two halves of the experiment stop comparing like with like. That is why METR are rebuilding the study from scratch.
There is a quieter, more uncomfortable reading too. From the outside, you cannot tell whether these developers refuse to work without AI because it makes them dramatically faster, or because coding without it has started to feel impossibly hard. A power user and a dependent behave identically. Only one of them is good news.
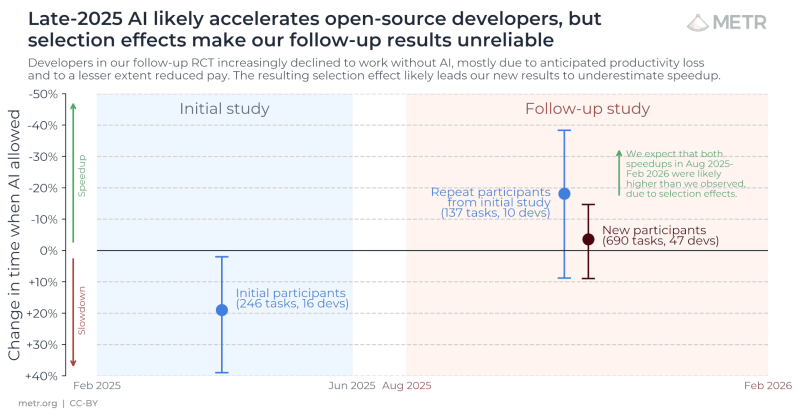
So what is the truth? The gains are real and they are specific. You earn them by aiming the tool with skill, and you forfeit them the moment you point it at work you cannot judge.
The output that matters is not yours. It's the team's.
Here is where I think it does not live up to the hype.
I am a senior Laravel developer working as a freelancer. That is the best case for AI uplift. Narrow domain, deep expertise, one person who can review every line and catch a wrong turn on sight. Of course my productivity is up.
Now scale that out. A real dev agency: a mix of juniors and seniors, project managers, shifting requirements, tight deadlines, code four people will touch this quarter. How much does team productivity actually rise when the juniors ship faster than they can review and the seniors spend their saved hours cleaning up behind them?
Then scale again to an enterprise. Hundreds of developers, compliance, legacy systems, coordination overhead.
My guess: the gains get more moderate the bigger the org gets. Individual speedups do not add up cleanly into organizational ones. They leak out through review, rework, and the slow tax of code nobody fully understands.
We have watched this movie before
When personal computers swept through offices in the 1980s, the productivity numbers stubbornly refused to move for years. Economist Robert Solow nailed it in 1987: "You can see the computer age everywhere but in the productivity statistics." The gains were real. They were just slower, smaller, and more uneven than the sales pitch promised. I would bet AI follows the same curve.
That delay even has a name: the Solow Paradox. New tools show up everywhere except the bottom line, until organizations slowly rewire how they work to actually use them. The jury on AI is still out. But if you are a leader budgeting for a 10x team next quarter, plan for moderate gains and be delighted if you are wrong.
Claim 4: "The more you use AI, the more productive you are. So we mandate and measure it."
This belief is quietly rewiring how teams are run.
Somewhere, a dashboard now tracks tokens burned per engineer. Somewhere, a manager counts AI-assisted pull requests and files it under performance. The logic feels airtight. The tool makes people productive, more usage means more productivity, so measure the usage and reward the heavy users.
But…
It's like rewarding a chef that used the most electricity to burn a steak overnight, and cooked nothing.
Cal Newport named the trap: pseudo-productivity, using visible activity as a stand-in for real output. It is a holdover from the factory floor, where output truly was countable. Longer shifts, more widgets.
Knowledge is not as simple to measure.
Tokenmaxxing sees motion, not value. It cannot tell you what actually shipped, whether it holds up in production, or whether it just bought three senior engineers a week of cleanup and quietly seeded an outage.
That last one is not hypothetical. In early 2026, Amazon's own cloud was hit by a run of outages linked to AI-assisted code changes. Amazon publicly disputed that AI was the cause and pointed to user error. But the response was telling. Soon after, Amazon began requiring a senior engineer to sign off on AI-assisted code changes before they could ship.
Picture the usage dashboard the week before. Plenty of AI-assisted commits, plenty of green, a very productive-looking team. Right up until the lights went out. 120,000 lost orders. Potentially hundreds of millions in lost revenue.
So what should a leader measure instead?
Newport's answer: obsess over the quality of what you produce.
Software had it figured out years ago, and now it seems we're going backwards. The industry already tried ranking engineers by lines of code and commit counts, then dropped it, because the best engineers often write less code, not more.
A decade of DevOps research landed on healthier signals: how often you ship, how long a change takes, how often it breaks, and how fast you recover. Every one of them measures the team's outcomes and the system's stability. Change-failure rate asks the exact question tokenmaxxing cannot: did the thing work, and did it stay up?
So, no surprise that Amazon is now backtracking after employees gamed the usage metrics.
I love this quote by Charlie Munger that explains why this was an inevitable outcome:
Show me the incentive, and I'll show you the outcome
Claim 5: "Now anyone can build software."
Anyone can produce code. Producing software is a different sport.
This is where two ways of working get confused, and Karpathy's framing is the cleanest cut I know: vibe coding raises the floor, agentic engineering raises the ceiling.
Vibe coding is prompt, glance, ship on feel. For a weekend script or a thing only you will run, it is a genuine gift. Use it there freely.
For client work, it is a slow-motion accident. You commit code you never read, built on decisions you never made.
Agentic engineering is the grown-up version. You stay the lead. The model is a fast, tireless junior who needs tight scope and a careful review of everything it returns.
And about juniors. The instinct is to hand these tools to junior developers as a crutch, a shortcut to "boost productivity." That is backwards.
This is what a professor at Georgia State University said it to his class:
LLMs are great resources for coding when you already know what you are doing. If you don't know what you're doing, they're actually really, really, really detrimental to learning.
That is the Dunning-Kruger effect wearing a productivity badge. A little knowledge plus a lot of confidence in the machine feels like progress, while the problems you cannot yet see quietly pile up behind you. Lean on the tool to avoid learning, and you do not get a shortcut. You get a debt.
Use it as a tutor, not a crutch
None of that means "never touch a framework you have not mastered." That is not the lesson.
There is nothing wrong with building on something new when the project calls for it. The danger is not the unfamiliar stack. The danger is using AI to paper over the unfamiliarity instead of closing it.
So flip the same tool from a crutch into a tutor…
When you work outside your expertise, slow the agent down and make it teach. Ask it to explain the decision, not just write it. Ask it to justify why this approach over the obvious alternative. Ask it to point you at the actual documentation, then go read it. Stay curious, and refuse to commit a single line you could not defend in a code review tomorrow.
Skip the understanding and you serve the machine. Build the understanding and the machine serves you.
Claim 6: "Stop reviewing. Embrace the slop. That's how you move fast."
This is the loudest one on my timeline, and the one that bites hardest in production.
The pitch goes like this.
Reading the diff is what slows you down. Refactoring is a nervous tic from the old world. Stop fighting the tools, let them do their job, ship the slop, keep moving. That, they say, is the new way to code.
Let me steelman it first, because there is a real version of this argument…
For vibe coding, they are right. A prototype, a demo, a weekend passion project, a personal tool. Maybe even an indie-hacked micro-SaaS (though I wouldn't ship software like that to real, paying users). Reviewing line by line is a waste. Embrace the slop, the slop is the point, move fast.
But quietly, the claim smuggles in a bigger one: that this is how you ship real software now. That is where it falls apart.
Slop you never read does not stay where you left it. It compounds. Every unreviewed shortcut becomes a foundation the next unreviewed shortcut is poured on top of. Six months in, you do not have a codebase. You have a haunted house, and nobody on the team will go into the basement.
Salesforce predicted 2026 the year of the technical debt.
So maybe it's in 2026 or 2027, but as the line in The Wolf of Wall Street goes:
Jordie, one of these days the chickens are gonna come home to roost.
And here is the cruel part.
The technical debt for some of the vibe-coded, token-maxxed codebases could get so bad that refactoring stops being an option. Because often faster and cheaper path forward becomes a full rebuild. You pay twice: once to write the slop, and again to throw it away and start over.
That is not fast. That is the most expensive way to move fast ever invented.
How to use LLMs like an expert
You might think the fix is to let the tool review its own work. Ship the slop, then ask the same model to clean it up. It cannot, and here is the reason that should settle it.
A model has no concept of being right. Researchers put it bluntly in a 2024 paper: LLMs are indifferent to the truth of their outputs. Apple's research team made a related case that the apparent reasoning is closer to an illusion of thinking.
So when something breaks at 2am, the model is not on the hook. As IBM frames it, an AI system can never be held accountable. You are.
This is my process for agentic coding with LLMs on client projects:
Start from your expertise. Aim the agent at problems you could solve yourself, just slower. You must be able to spot a wrong answer on sight.
Think before you prompt. Decide what and why, break it into smaller tasks, ask for a plan, and make sure to read the plan. I use Addy Osmani’s skill to turn agent into an interviewer to help me flush out the details I may have missed.
One task at a time. LLMs perform best in a narrow scope. So more iterations over one-shotting. Clear context more often.
Review like you mean it. I use
/reviewand then/code-simplifycommands from the Agent Skills plugin, and then I thoroughly review every line after. If a diff confuses me, I do not commit until I genuinely understand it. I turn an agent into a tutor. Because at the end of the day, for me, there are more important things than moving as fast as possible.
Vibe coding has a half-life
Code you didn't read becomes code nobody understands becomes code nobody dares to change. The bill for skipped review arrives months later, with interest, usually during an incident.
Claim 7: "GPT 5.5 just dropped. Switch everything."
New models drop every couple of months. First Codex led, then Claude, then Gemini, then Claude again. Now it seems Codex is back on top… It is exhausting to keep up. And tearing up a workflow you just got comfortable with, every time the leaderboard reshuffles, costs you more than it gives.
The biggest jump in your code quality is usually not a bigger, better model or a cleverer prompt. It is a more opinionated framework.
Ben Bjurstrom put it well:
Your AI is only as good as the decisions it doesn't have to make.
Every fork in the road is a chance to hallucinate a wrong turn. Which auth library, which queue, which of nine competing packages. A framework with strong opinionated defaults deletes those forks. One blessed way to do auth, queues, mail, caching, and the model has read that one way ten thousand times.
This is exactly why I am all-in on the Laravel ecosystem. The conventions that make it pleasant for humans make it legible for machines, for the same reason: less to guess. Three things stack the deck further:
A type checker as second reviewer. PHPStan catches the model's mistakes automatically. Have the agent run static analysis after every change, and a class of confident errors dies before you see it.
Project-aware context. Tools like Laravel Boost feed the agent your real schema, docs, and errors, so it stops inventing columns that do not exist.
One platform, not eight services. A typical Next.js project might wire up eight separate third-party services for storage, cache, and queues. Less surface area means fewer places for the model to get lost.
The smartest model on a vague, sprawling stack still guesses. A capable model with guardrails rarely has to.
Claim 8: "Spin up 100 agents in the cloud. They work 24/7 while you sleep."
Wrong constraint.
The dream is intoxicating. An army of tireless employees in the cloud, shipping features while you sleep. Ten times the developers, none of the payroll.
Here is what the pitch quietly skips…
Karpathy, who has every reason to be bullish on agents, names the real limit:
Information still has to make it into my brain. I am becoming the bottleneck of even knowing what we are trying to build, why it is worth doing, and how to direct my agents.
So the number of agents was never the bottleneck. Your understanding is.
Spin up one agent or a hundred, and every one of them still routes its output back through a single human who has to know what is being built and whether it is right. More agents do not widen that channel. They flood it.
And there is already a name for one person trying to track a hundred parallel streams of work. It is multitasking. The science on it is neither new nor kind. The APA puts the productivity loss from task-switching at as much as 40%.
You do not become ten developers by opening ten sessions. You become one stretched person doing ten things worse.
Agents scale the typing. They do not scale the understanding.
Claim 9: "AI is coming for your job."
If you take the headlines at face value, it does look scary.
I'm not going to pretend that I haven't been anxious in the past year or haven't questioned my future.
But when a company cuts thousands of jobs and credits "AI productivity," be suspicious. Many of those companies overhired for years, ran inefficiently while capital was cheap, and watched their stock fall 50-80% in the last year. The board wanted a story. AI became the story.
The trend of CEOs blaming layoffs on the productive capabilities of AI even earned its own term: "AI washing".
Economists are blunt about the gap: Oxford Economics noted in early 2026 that if AI were genuinely replacing labor at scale, productivity growth should be accelerating, and broadly it is not.
So run the logic yourself. If a tool truly made your people 10x more productive, would you fire some of them? Or would you set them loose to make better products, ship more of them, and take more of the market? A layoff blamed on a robot is often a confession about management, dressed up as a story about AI.
This clears the way to see what AI actually does to the job, and it is not to erase it.
If agents handle more of the execution, the value is not in typing code (has it ever been?).
You can outsource your thinking, but you can't outsource your understanding.
The work shifts from writing every line to directing the production and owning the result. Taste, architecture, judgment, whether the whole system makes sense. That is not a consolation prize. It is the actual job, and it asks more of you, not less.
The whole field manual, on one card
AI is not a mind. It is a pattern machine. Useful, not accountable.
You cannot opt out. You can choose how. The how is the entire ballgame.
The speed is mostly a feeling until you measure it.
Usage is not value. Counting tokens measures motion, not work.
Anyone can produce code. Producing maintainable software still takes a developer.
An opinionated framework (like Laravel) beats a smarter model.
More agents do not widen the bottleneck. Understanding does not parallelize.
The model is indifferent to truth, so review is not optional.
Your job is not disappearing. It is concentrating into judgment.
So how does this end for us?
Father John Culkin, a priest and media scholar, back in 1967, unpacked how the media we build reshapes us in turn:
We shape our tools, and thereafter our tools shape us.
The developers who keep deepening their understanding will become the true 10x engineers. They'll get faster, sharper, more effective every year, and harder to replace because of it.
The ones who use it to skip the understanding will lose twice. They'll ship software they cannot defend while their own skill quietly atrophies, until they become the easiest person on the team to let go.
So keep your hand on the wheel and stay clear-eyed out there.
